Was zählt?
Zu den Modalitäten chiffrierter Güterabwägungen in den (pseudo–)sozialen Netzwerken
Ursula Ganz-Blättler, Universität St. Gallen
Aufsatz zum Kolloquium 2019
Einleitung
Am Anfang dieses Aufsatzes standen allgemeine Überlegungen zum längst als selbstverständlich erachteten Gebrauch von Nutzerdaten durch die institutionellen Betreiber von sozialen Netzwerken wie facebook oder Twitter. Ich habe mich gefragt, was uns die freiwillig gewählte Abhängigkeit von diesen primär kommerziell ausgerichteten Kommunikationsplattformen auf längere Sicht einbrocken mag an (… zum Beispiel) eingeschränkten Sichtweisen auf die Welt und entsprechenden Informationslücken, aber auch an Vertrauenskrisen, wenn wir die „doppelte Realität“ des Netzes (Luhmann 1996) mit der uns tatsächlich umgebenden Wirklichkeit verwechseln.
Dazu gesellte sich eine ganz bestimmte Sorge hinsichtlich der weitreichenden Definitionsmacht, die solche grossflächig operierenden „Datenstaubsauger“ innerhalb der weltweiten Netzgemeinschaft ausüben. Ich habe mich gefragt, welche Reputations- und anderen Schäden entstehen, wenn die Netzwerkverantwortli-chen bestimmte Nutzer aufgrund angeblicher Regelverstösse verwarnen, blockieren oder gar von der Plattform verbannen. So etwas kann ja auch als Folge einer Verwechslung, einer Denunziation oder aufgrund simpler Programmierfehler vorkommen und nebst erheblichen wirtschaftlichen Nachteilen durchaus eine Art „sozialen Tod“ nach sich ziehen.
Als Beispiel der Fall des You-Tube-Kanalbetreibers Nicholas Oyzon, der regelmässig Kommentare zum Spiel „Pokemon Go“ abgibt. Der junge Mann verwendete Anfang 2019 eine unter Spielern und Spielebeobachtern gängige Abkürzung, die zufällig auch in pädophilen Zirkeln als Geheimcode gebräuchlich ist. Weil die automatischen Security-Bots nur das Kürzel, aber nicht die jeweilige Bedeutung zu erfassen in der Lage waren, warfen sie den vermeintlichen Porno-Konsumenten aus dem Netz, was nicht nur zur vorübergehenden Schliessung des populären Kanals führte, sondern auch mit erheblichen finanziellen Einbussen und einem – viel schwerer zu gewichtenden – Imageschaden bei den jugendlichen Followern des Spiel-Experten verbunden war. Vgl. dazu das Spielermagazin Polygon. (27.07.2020)
Das allgemeine Interesse an solchen und anderen Kommunikationspannen führte mich zur weiterführenden Frage, was uns blühen mag, wenn wir in unseren alltäglichen sozialen Kontakten zunehmend auf maschinell erzeugte, lernfähige Gegenüber setzen. Solche maschinellen Gegenüber können als Vertrauensinstanzen und Dialogpartner fungieren und zwischenmenschliche Kontakte ergänzen: Beispiele sind etwa die bereits vertrauten Navigationsgeräte im Auto, aber auch sogenannte Smart Speaker – das sind mit dem Internet verbundene Lautsprecher, die auf akustisch geäusserte Wissensfragen ebenfalls akustisch antworten (vgl. https://de.wikipedia.org/wiki/Smart_Speaker). Solche Geräte können aber auch durchaus die Funktion von Bezugspersonen im Sinne eines identitätsstiftenden Umfelds übernehmen: Dann ersetzen sie möglicherweise zwischenmenschliche Kontakte, was wiederum weitreichende Anschlussfragen hinsichtlich der Vergesellschaftung und Vergemeinschaftung von Menschen (… jeglichen Alters) stellt.
Da schon heute solche künstlichen Ansprechpartner – in ganz unterschiedlichen Formen und Funktionen – unser Leben bevölkern, lohnt sich der Blick auf die im Hintergrund tätigen, elektronischen Bots, die als stille Helferlein in unzähligen Anwendungsgebieten tätig sind. Sei es, dass sie mir als Nutzerin eines sozialen Netzwerks individuell zugeschnittene Inhalte nach Mass empfehlen und über Werbeanzeigen bestimmte Kaufinteressen triggern, oder mich an die Geburtstage meiner friends erinnern und auch sonst nach Kräften in meiner digitalen Komfortzone bzw. „Wohlfühloase“ einbehalten wollen (dazu Pybus, 2015).
Dass es da nur schon aufgrund der institutionell bedingten Intransparenz der zugrundeliegenden Geschäftsmodelle zu Irrtümern und Interessenskonflikten und damit zu Spannungen kommen muss, ist nachvollziehbar. Zur Problematik entscheidend bei trägt die globale Popularität und damit die schiere Grösse der steuernden Strukturen im Hintergrund. Beziehungsweise der Umstand, dass alle Abläufe automatisiert sind – und kaum jemand in diesen unübersichtlichen „Bienenstöcken“ bereit zu sein scheint, als Ansprechperson zu fungieren und verlegerische Verantwortung für die Mensch-Maschine-Kommunikation zu übernehmen.
Davon handeln die folgenden Ausführungen. Und zwar ausgehend von ein paar einführenden Betrachtungen technischer Art.
Die mathematische Komponente
Mit dem Begriff der „selbstlernenden Algorithmen“ werden in der Informatik Softwareprogramme bezeichnet, deren Rechenvorgänge Datenstrukturen erkennen und entsprechende Informationen aufgrund vorangehender Programmieranweisungen selbständig speichern und verarbeiten können. Solche „programmierten Programme“ werden etwa von Internetplattformen (sogenannten social media wie facebook, Twitter, You Tube) eingesetzt, um grosse Mengen an Text-, Audio- und Bild-Daten nach bestimmten vorgegebenen Bedeutungsmerkmalen zu durchforsten. Entspricht ein aufgefundenes semantisches Feld den gesuchten Kriterien, wird der betreffende „Inhalt“ einem Set vordefinierter Befehle unterworfen. Im Zentrum der auszuführenden Operation stehen bestimmte Handlungsanweisungen, die die programmierende Person dem Rechenprogramm einschreibt, ehe dieses auf die Daten „losgelassen“ wird
Der Begriff „Algorithmus“ ist nicht etwa altgriechischen Ursprungs, wie man vermuten möchte, sondern leitet sich vom Namen des arabischen Mathematikers Al-Chwarizmi ab, der im 9. Jahrhundert nach Christus ein mathematisches Lehrbuch verfasste (dazu ausführlicher Zweig 2019, 51)
Sebastian Dörn (vgl. https://sebastiandoern.de/algorithmen/) verweist zur Veranschaulichung des Prinzips auf ein einfaches Backrezept, dessen Handlungsanweisungen theoretisch als lineare Folge von Rechenoperationen dargestellt (= implementiert) werden können: Zunächst sind bestimmte Zutaten aufzutreiben und in einer Schüssel zu mischen (= addieren). Zwischendurch ist die Masse umzurühren, damit sie zu einem glatten Teig wird: Ein Algorithmus könnte an diesem Punkt einen Roboter steuern, der nach jedem Umrühren die Konsistenz prüft und selbständig den Rührvorgang abbricht, sobald der Teig der gewünschten Konsistenz entspricht (= weiterrühren: ja / nein). Schliesslich ist – vor dem eigentlichen Backvorgang – ein weiterer, dritter Rechenvorgang angezeigt, der das Einfüllen des Teigs in kleine Backformen veranlasst und den Prozess vie Zähler überwacht (Muffinform: i=1 / i<12).
Gemäss diesem (verhältnismässig einfachen) Beispiel lassen sich Algorithmen als rechnerisch aufbereitete Handlungsanweisungen definieren, die Computer in die Lage versetzen, ohne menschliches Dazutun grosse Mengen von im Internet zirkulierenden Daten zu bestimmten interessierenden Phänomenen zu sammeln und zu aggregieren mit dem Zweck, sie in strategischer Weise nach gewünschten Parametern zu durchsuchen. Dabei sind Menschen entweder nur als Datenquellen von Interesse und werden ohne Rückschluss auf die persönliche Identität zitiert mit dem Ziel, möglichst umfangreiche Datensätze zu generieren. Oder sie stehen im Zentrum des eigentlichen Auswertungsinteresses: Dann haben wir es mit Fällen von (legaler oder illegaler) Spionage zu tun mit dem Ziel der Einstellungs- oder Verhaltensänderung bei den observierten Personen.
Das Vorgehen dient jedenfalls dazu, gültige Aussagen zu formulieren zu besagten Phänomenen: Es wird zum Beispiel benutzt, um Vorannahmen hinsichtlich zukünftiger Ereignisse zu treffen oder Empfehlungen hinsichtlich noch zu treffender Entscheide abzugeben. Ein zunehmend wichtiger Aufgabenbereich von Algorithmen ist es, mit den im Netz gesammelten Datenschnipseln Programme zu füttern, die lernen sollen, wie Menschen zu „denken“ bzw. zu funktionieren. Hier ist es die schiere Menge an verarbeiteten Informationen, die die Effizienz einer maschinellen Text-, Bild- oder Geräuscherkennungssoftware steigert – bis zum Punkt, an dem solche „Bots“ selbständig komplexe Entscheide zu treffen scheinen, während sie doch nur ein vom menschlichen Vorbild abgegucktes Verhalten gemäss der statistischen Wahrscheinlichkeit, richtig zu liegen, reproduzieren – ein klassischer Fall von Mimikry bzw. „so tun, als ob“.
Weil die in solchen Datenmaterialien nachgesuchten Strukturmerkmale in der Regel nicht mit Absicht bzw. wissend von der Urheberschaft in die entsprechenden Datensätze hinein gelegt wurden, lässt sich das so betriebene data mining auch als Zweitverwertung von äusserst wertvollem „Datenmüll“ bezeichnen. Das heisst: So wie die Historikerin im Archiv umfangreiche Bestände mittelalterlicher Geburtsregister konsultiert, um via Direktvergleich und Hochrechnungen zu plausiblen Annahmen hinsichtlich allgemeiner Bevölkerungsentwicklungen in der fraglichen Zeitperiode zu kommen, lassen sich grundsätzlich alle digitalen Überreste von Kommunikationen im Netz für sekundäre Auswertungen beiziehen … unter der Voraussetzung natürlich, dass die einschlägigen Verfahren des Sammelns und Sichtens
- technisch machbar,
- dem geplanten Vorhaben tatsächlich dienlich sowie
- rechtlich vertretbar sind.
Zur typologischen Unterteilung faktenorientierter Quellen hinsichtlich ihrer Funktion als „Tradition“ oder „Überrest“ vgl. das historiographische Unterrichtstool Ad fontes der Universität Zürich unter www.adfontes.uzh.ch/tutorium/quellen-auswerten/quellenkritik-und-quellentypologien/schriftliche-quellen-und-sachquellen (07.01.2020)
Datenauswertungen so und so
Die Bandbreite der bisher geschilderten automatisierten Such- und (Be-)Handlungsoptionen im Netz ist schon heute beeindruckend, wie Sebastian Dörn (vgl. oben) an einigen gebräuchlichen Beispielen aufzeigt. Ein „Sammeln und nach der Formel xy auswerten“ bedeutet für die Marketingabteilung werbetreibender Social-Media-Partner, dass sich per Maschinen-Entscheid individuelle Nutzerprofile anlegen und Kaufangebote ad personam formulieren lassen. Der Befehl „Suchen nach Gleichwertigem und in die Angebotsschlaufe einfügen“ schlägt Kunden von Online-Shops weitere ähnliche Gegenstände wie den eben angeschauten vor und nimmt so die Entscheidung ab, was jemand als nächstes in Betracht ziehen möchte. Ein dritter, in der datenverwaltenden Praxis von Social-Media-Plattformen besonders häufiger Befehl lautet: „Objekt aus dem Angebot entfernen / den Urheber auf den Index setzen“.
Dass im letzteren Fall in der Regel der Schutz vor ungewollten (zum Beispiel gewalthaltigen oder pornografischen) Inhalten im Vordergrund steht, ist zwar leicht verständlich und auch durchaus nachvollziehbar. Es kommt hier aber in entscheidender Weise auf den Kontext an: Beim Umgang mit präventiven Schutzmassnahmen stellt sich die grundsätzliche Frage, wer das uneingeschränkte Recht auf Schutz wovor geniesst, wer die Verantwortung für das Zensieren trägt – und wem es letztlich zukommt, die entsprechenden Programme zu programmieren,
- mit welchen Eigeninteressen,
- mit welcher tatsächlich zu erwartenden „Treffsicherheit“
- und mit welchem Transparenzgebot hinsichtlich der Kennzeichnung der Schutzabsicht gegenüber direkt oder indirekt Betroffenen.
Dazu kommt als Anschlussfrage: Was ist, wenn der search-and-destroy-Befehl seiner primären Lösch-Aufgabe nicht „am hellichten Tag“ und öffentlich, sondern grundsätzlich diskret und auf leisen Sohlen nachgeht?
Letztlich stellen gerade solche zuletzt als Beispiel genannten „intelligenten“, aufgrund sprachlicher Kriterien und mit mathematischer Präzision ein- und ausschliessenden Überwachungstechniken die alte Frage nach der Verantwortung von (programmierenden, aber auch schreibenden, lesenden und handelnden) Menschen in einer freiheitlichen Gesellschaft neu: Wer aggregiert und sortiert, nach welchen Spielregeln und gesellschaftlichen Normen?
Aggregieren und segregieren im Fokus
Im folgenden stelle ich kurz ein paar aktuell diskutierte Anwendungsgebiete von Algorithmen vor, die aus unterschiedlicher Perspektive Schlaglichter auf die aus menschlichen Kommunikationen gewonnenen Daten als „semantisches Feld“ werfen.
• Der eine Fall nimmt den Begriff „Überwachung“ wörtlich und betreibt das Aggregieren von personenbezogenen Daten im Sinne einer flächendeckenden behördlichen Dauerbeobachtung mit dem Ziel, Regelmissachtungen festzustellen und zu ahnden.
• Der andere Fall versteht Menschen wie dich und mich nicht allein als Datenlieferanten, sondern auch als direkte oder indirekte Nutzniesser von rechnerisch aufbereiteten Computerdaten – sei es im Bereich einer gewissermassen „öffentlich-rechtlich“ betriebenen Bürgeraufklärung oder aber im Bereich der gewinnorientierten Entwicklung und Optimierung elektronischer Gadgets für eine kaufkräftige Kundschaft.
Mit dem Begriff des „semantischen Feldes“ suche ich dabei zu differenzieren, dass Menschen
• im einen Fall als eigentliche Objekte der Betrachtung bzw. als Individuen aggregiert (und, gleichzeitig: segregiert) werden, wobei bestehende Machtgefälle bestätigt oder aber neue Machtgefälle generiert werden, mit schwer abschätzbaren Folgekosten für die sozialen Gefüge, die es betrifftt.
• Im anderen Fall bleiben die mensch-generierten Daten wie gesagt anonymisiert und finden lediglich im Sinne von Vergleichsgrössen und zu Modellierungszwecken Verwendung. Das schliesst zwar missbräuchliche (Weiter-)Instrumentalisierungen der aggregierten Daten – z.B. zu Observierungszwecken – nicht aus, sieht aber solche Zweitverwertungen jenseits einer gemeinschaftsfördernden oder kommerziellen Primärnutzung zumindest nicht vor.
Zweig (2019, 77) betont, dass durch Algorithmen betriebene Strukturierungsvorgänge nicht von anderer Qualität und damit auch nicht „böser“ sind als Strukturierungsvorgänge, die menschlichen Beobachtern obliegen: Letztere sind bloss „milliardenfach langsamer“. Die Verantwortung für Observierungsvorgänge hängt – in beiden Fällen – von der Übersicht der programmierenden Instanzen hinsichtlich des In- und Outputs ab (ebd., 79): „Je mehr Informationen und Kontrolle Algorithmendesigner*innen über den genauen Einsatzort (den Kontext) des Algorithmus haben, desto höher ist ihre Verantwortung für seine Resultate und deren Konsequenzen.“
Die amerikanische Ökonomin Shoshana Zuboff hat mit ihren Warnungen vor dem, was sie in aller Deutlichkeit „Überwachungskapitalismus“ nennt (Zuboff 2018, und Naughton 2019) eine breite Öffentlichkeit erreicht und wachgerüttelt. Unter diesen Begriff fällt vor allem, was Menschen (als Individuen oder als soziale Aggregate) via automatisierte Fütterung (und: Filterung) von Wissensbeständen in vorgegebene bzw. erwünschte Verhaltensmuster zwingen will.
Solche manipulativen Manöver werden einerseits im Interesse autoritärer Staaten wie China betrieben, wo unerwünschte Verhaltensmuster mehr oder weniger subtil durch soziale Ächtung geahndet werden. Das Stichwort hier heisst Sozialkredit (vgl. https://de.wikipedia.org/wiki/Sozialkredit-System, mit weiteren Verweisen). Sie lassen sich aber auch im Zusammenhang mit individualisierter, strategischer Wahlwerbung nachweisen, an deren Ursprung das gezielte Streuen von Falschinformationen über unliebsame Gegner steht. Ein anschauliches – fiktives – Beispiel dafür, wie sozialer Druck über Beliebtheitsskalen funktioniert bzw. funktionieren könnte, ist die wirklich beängstigende Auftaktfolge der dritten Staffel der US-amerikanischen Netflix-Serie „Black Mirror“, in der eine junge Frau aufgrund der sozialen Ächtung, die sie in ihrem materiell bessergestellten Ausgangsmilieu zu erfahren glaubt, in eine existenzbedrohende Abwärtsspirale gerät (vgl. den Trailer unter www.youtube.com/watch?v=R32qWdOWrTo).
Wie das Aggregieren von Daten zum Erhalt von Vergleichsgrössen funktioniert, illustriert hingegen die Werbung für eine Korrektur-App namens „Grammarly“, die bis dahin nur im englischen Sprachraum existiert. Hier sind es Bruchstücke geschriebener Sprache, die gesampelt und als „mehr oder weniger korrekt“ kategorisiert werden, um dann – in der Anwendung durch grammatikalisch unsichere (oder: perfektionistische) Textautoren – sekundenschnell passende Ersatzformulierungen vorzuschlagen (vgl. www.youtube.com/watch?v=_yj-hjzql3I).
Der selbstlernende Aspekt solcher Programme bringt es mit sich, dass man sich schon heute fragen muss, was es mit den verbreiteten Bitten um „Aufzeichnung des Kundengesprächs zu Schulungszwecken“ im direkten Telefonkontakt etwa mit Banken oder Versicherungen auf sich hat. Wie Zweig beiläufig erklärt (2019, 117/118) ist es durchaus möglich, dass mit den „Auszubildenden“ nicht etwa menschliche Lehrlinge gemeint sind, die „mithören“, sondern sogenannte KIs, also Künstliche Intelligenzen – deren Aufgabe es ist, aus unserem Alltagskauderwelsch selbständig verständliche Textstrukturen herauszufiltern, für zukünftige Anwendungen, die derzeit noch gar nicht angedacht sind bzw. in den Kinderschuhen stecken.
Zum Abschluss dieses kleinen tour d’horizon durch die schöne neue Welt der computergenerierten Aggregierungs- und Segregierungsprozesse gehe ich noch kurz auf die zentrale Bedeutung der Programmierung von Programmen ein, und zwar gemäss einem Strukturvorschlag, den der deutsche Kommunikationswissenschaftler Manfred Rühl (1995) ursprünglich für die Dualität der Fernsehprogramme in den 80er und 90er Jahren entwickelt hat: Er verwies darauf, dass „Programme“ niemals nur als zeitliche Abfolgen von bestimmten Schritten zu lesen sind (… analog zu dem eingangs zitierten Rezeptvorschlag, wie ihn Sebastian Dörn zum Vergleich beizieht), sondern vor allem auch als Ausdruck einer Programmierung, die einer bestehenden – und damit zwingend menschgemachten, gesellschaftliche Zustände abbildenden oder diese in Frage stellenden – Logik folgt.
Entsprechend dem Beispiel des von Rühl näher betrachteten (Leit-)Mediums Fernsehen lassen sich auch im Falle der datenverwertenden künstlichen Intelligenzen vornehmlich jene beiden Systemlogiken identifizieren, die unsere Mediensysteme insgesamt kennzeichnen: das öffentlich-rechtliche System, welches Menschen (in herkömmlichen Demokratien) als für ein Gemeinwohl mitverantwortliche Bürger sieht und anspricht, und das liberale, von wirtschaftlichen Überlegungen geprägte privat-rechtliche System, welches dieselben Menschen in erster Linie als nach der Erfüllung individueller Wünschen strebende Konsumenten versteht und anspricht.
Zwei soziale Plattformen sollen diesen (zwar theoretischen, aber in der alltäglichen Kommunikationspraxis durchaus wirkmächtigen) Unterschied illustrieren, in aller Kürze:
• Unter dem Link https://yuka.io/en/ lässt sich eine von François Martin, Benoît Martin und Julie Chapon entwickelte App auf das Smartphone laden, welche die Strichcodes von Esswaren und Kosmetikprodukten nach gesundheitsgefährdenden Stoffen scannt. Bemerkenswert daran ist einerseits, dass sich die Nutzer der App als (Netz-)Gemeinschaft sehen, die nach Möglichkeit zum Wissen über gesundheitsschädigende Stoffe in Esswaren und Kosmetikprodukten beitragen möchten. Bemerkenswert ist aber auch, dass die Entwickler der App offen kommunizieren, welche Regeln sie beim Sammeln und Aggregieren von (Nutzer-)Daten befolgen bzw. welche Geschäftspraktiken aus ethischen Gründen ausgeschlossen sind (weiterführend dazu Laeri und Léguillon, beide 2019).
• Das Gegenbeispiel – und damit schliesst sich der Kreis – sind kommerziell orientierte soziale Netzwerke wie facebook, Twitter oder auch YouTube, die mit dem beständigen Interessenskonflikt leben müssen zwischen dem, was regelmässige Nutzer dem Netzwerk anvertrauen möchten, und dem, was die Betreiber solcher Netzwerke gerne von ihren Nutzern an weiter verwertbaren Daten erhalten würden. Dazu diese Illustrationen https://abload.de/img/stagegifcsf2w.gif (Graphik von ugb):
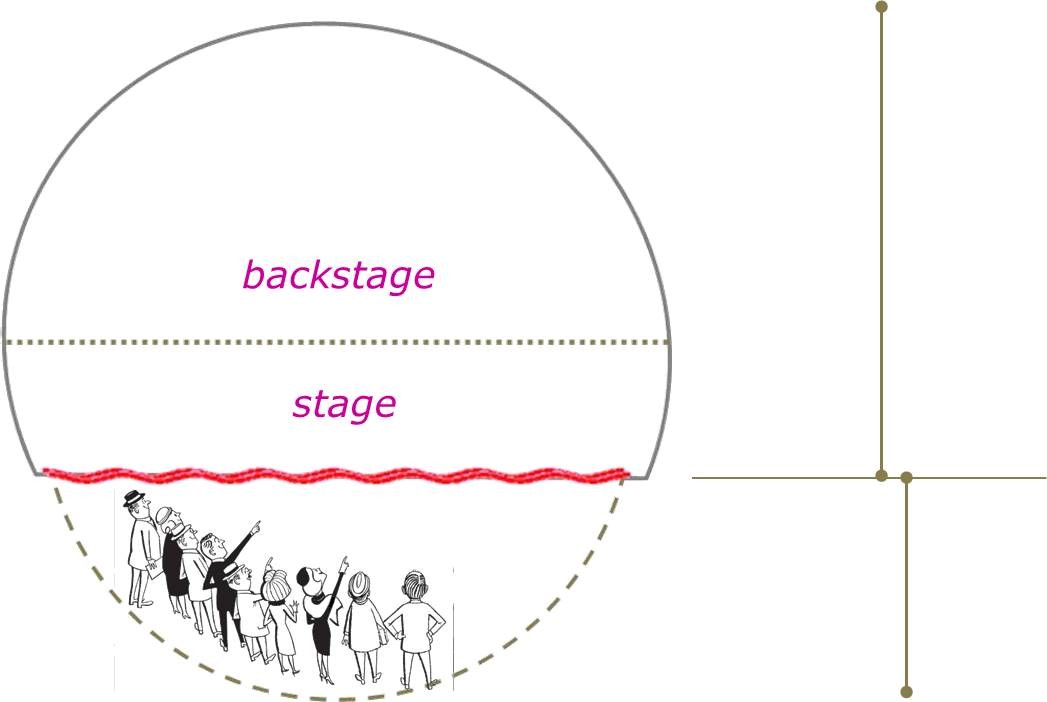
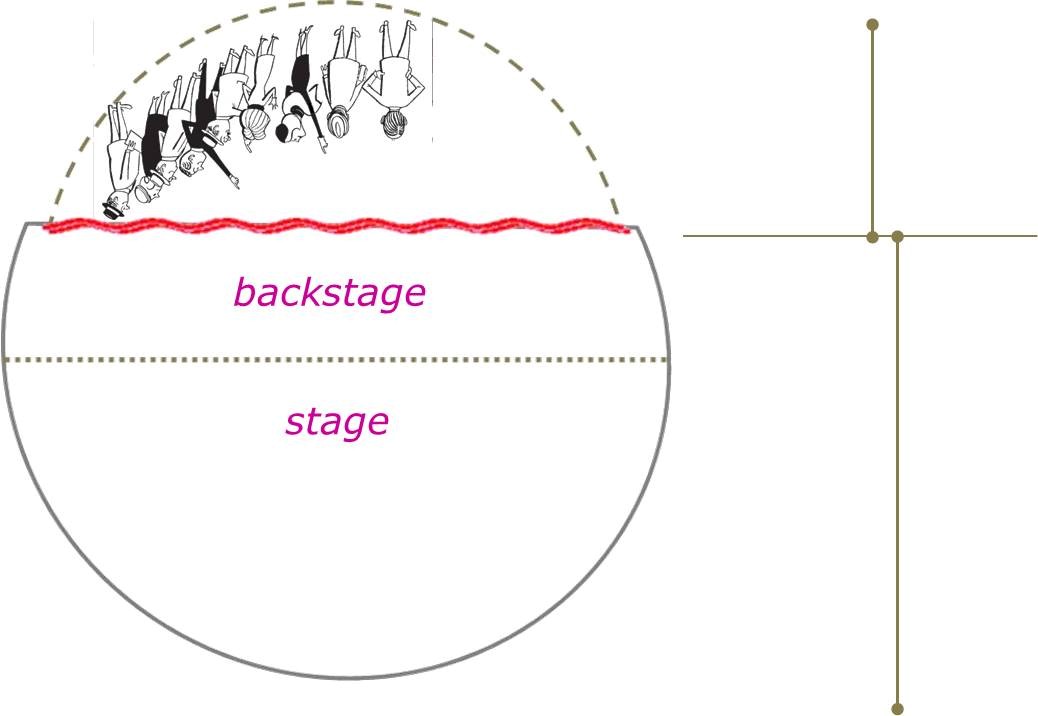
Je nach Betrachterstandpunkt, der den fraglichen Raum in Vorder- und Hinterbühne sowie Zuschauerraum unterteilt, erscheinen solche soziale Netzwerke vordergründig als Orte der Vergemeinschaftung, wo man sich über gepostete Eigen- und weitergepostete Fremdproduktionen angeregt unterhält. Oder aber sie erscheinen als Orte des emsigen Datensammelns und –aggregierens, die den Nutzern vorwiegend die Funktion von „Weidevieh“ zugestehen, welches den Betreibern der Plattformen gegen das Gefühl von Vergemeinschaftung die eigene Datenproduktion gratis und franko zur Weiterverwendung zur Verfügung stellt.
Schliessen möchte ich nicht mit einer Güterabwägung, welche Datennutzungen insgesamt „besser“ sind oder wünschbarer. Und zwar deshalb, weil sich hier wie gesagt ganz unterschiedliche Logiken begegnen, die sich genau wie Äpfel mit Birnen schlecht vergleichen lassen. Im Sinne einer umfassenden Biodiversität kann man höchstens für eine gleichberechtigte Existenz unterschiedlicher Systeme plädieren. Stattdessen möchte ich mit der Frage enden, ob es wirklich Sinn macht, die zu unterschiedlichen Zwecken erhobenen Datensammlungen ohne Wenn und Aber den jeweiligen Nutzniessern zu überlassen, anstatt eigene – und seien es kommerzielle – Interessen geltend zu machen. Für ein fröhliches Feilschen in diesem Bereich setzen sich zum Beispiel Eric A. Posner und E. Glen Weyl ein (Posner / Weyl 2019), die den Vorschlag machen, persönliche Daten als Resultat von „Arbeit“ zu verstehen, die wie jede andere Arbeitsleistung auch angemessen zu honorieren ist bzw. wäre.
Das von den beiden Autoren zitierte „A Penny for your Thought“ (ibid. 243) ist dabei nur eine von vielen möglichen Formen der Kompensation bzw. einer Wertschätzung von all dem, was bisher noch als unbezahlte Arbeit „durchgeht“, in der Welt der maschinell betriebenen Aggregierungen menschgemachter und menschbezogener Kommunikationsspuren hinter den Kulissen der (pseudo-)sozialen Netzwerke.
Letztlich bleiben derzeit noch viele Fragen offen – einfach, weil die Anwendungen noch so neu sind und die entsprechenden politischen, rechtlichen und wirtschaftlichen Strukturen noch in den Kinderschuhen stecken. Eine Forderung lässt sich sicher stellen, die in ihrer allgemeinen Verbindlichkeit auf die gemeinsame Verantwortung aller Betroffener verweist – und damit auch auf die Verantwortung aller, die die sozialen Medien und Gadgets tagtäglich nutzen und damit zu den Datenbergen beitragen, die alte und neue Begehrlichkeiten wecken. Wenn es darum geht, Kriterien zu erarbeiten, die es uns auf die eine oder andere Weise Aggregierten (wieder) erlauben, die Chiffrierprozesse als solche zu beurteilen / bewerten (was eine wichtige Voraussetzung wäre zum Einwilligen ins Aggregieren), dann brauchen wir zum Anstoss solcher Prozesse noch sehr viel mehr Licht und Wissen um die Zusammenhänge.
Überlässt man nämlich das Nachdenken über die Zusammenhänge den verantwortlichen Betreibern und technik-affinen Hintermännern, wird statt Aufklärung vielmehr Verklärung betrieben, und die tentativen Voraussagen lassen sich als selbsterfüllende Prophezeiungen lesen. Oder, wie es Elena Esposito und Rebekka Kahn formulieren (beide 2018): Der Algorithmus wird zur übergeordneten, quasi-göttlichen Instanz.
Materialien zu Anschauungszwecken:
Grammarly-Werbung vom 27.02.2019; vgl. www.youtube.com/watch?v=_yj-hjzql3I (07.01.2020)
Zirkulin-Werbung (mit Lauterkennungsprogramm eines handelsüblichen Smart Speakers) vom 09.08.2019; vgl. www.youtube.com/watch?time_continue=20&v=68Co7bsL5k4 (07.01.2020)
Netflix-Featurette zu „Nosedive“ (1. Folge der 3. Staffel von Black Mirror): vgl. www.youtube.com/watch?v=R32qWdOWrTo (07.01.2020)
Bibliografie:
DÖRN, Sebastian: Algorithmen verstehen und deren Einsatzgebiete kennenlernen. Blogeintrag auf Website des Autors; vgl. https://sebastiandoern.de/algorithmen/ (07.01.2020).
ESPOSITO, Elena: Zukunft und Ungewissheit in der digitalen Gesellschaft. Referat 2018; vgl. Videofassung unter https://www.youtube.com/watch?v=f7uWDhD9GWI (14.08.2020).
GRASSEGGER, Hannes / KROGERUS, Mikael (2018): „Ich habe nur gezeigt, dass es die Bombe gibt“. In: Tages-Anzeiger vom 20.03.2018; vgl. www.tagesanzeiger.ch/ausland/europa/diese-firma-weiss-was-sie-denken/story/17474918 (07.01.2020).
HÖFLICH, Joachim R. (1995): Vom dispersen Publikum zu "elektronischen Gemeinschaften". Plädoyer für einen erweiterten kommunikationswissenschaftlichen Blickwinkel. In: Rundfunk und Fernsehen 43, 4, S. 518-537.
KAHN, Rebecca: Omen und Algorithmen. Eine Antwort auf Elena Esposito. Blog-Eintrag auf der Website des Alexander-Humboldt-Instituts für Internet und Gesellschaft 2018; vgl. https://www.hiig.de/omen-und-algorithmen-eine-antwort-auf-elena-espositos-zukunft-und-ungewissheit-der-digitalen-gesellschaft/ (14.08.2020).
KRÜGER, Julia (2018): Wie der Mensch die Kontrolle über den Algorithmus behalten kann. Blogbeitrag in: Netzpolitik.org vom 19.01.2018; vgl. https://netzpolitik.org/2018/algorithmen-regulierung-im-kontext-aktueller-gesetzgebung/ (07.01.2020).
LAERI, Patrizia (2019): Revolution am Regal (Blogbeitrag). In: Blick vom 19.09.2019; vgl. https://www.blick.ch/meinung/kolumnen/aufbruch-mit-patrizia-laeri-revolution-am-regal-id15521467.html (07.01.2020).
LÉGUILLON, Sara (2019): Yuka, l’application qui analyse les produits alimentaires, arrive en Suisse. In: Le Temps vom 01.04.2019; vgl. www.letemps.ch/economie/yuka-lapplication-analyse-produits-alimentaires-arrive-suisse (07.01.2020).
LUHMANN, Niklas (1996): Die Realität der Massenmedien. Opladen: Verlag für Sozialwissenschaften.
NAUGHTON, John (2019): The goal is to automate us. Welcome to the age of surveillance capitalism. In: The Guardian vom 20.01.2019; vgl. www.theguardian.com/technology/2019/jan/20/shoshana-zuboff-age-of-surveillance-capitalism-google-facebook (07.01.2020). Deutsch erschienen als: Tyrannei, die sich von Menschen ernährt. Shoshana Zuboff im Interview. In: Der Freitag 13 / 2019; vgl. www.freitag.de/autoren/the-guardian/tyrannei-die-sich-von-menschen-ernaehrt (07.01.2020).
POSNER, Eric A. / WEYL, Glen (2018): Data as Labor. Valuing Individual Contributions to the Digital Economy. In: Dies.: Radical Markets. Uprooting Capitalism and Democracy for a Just Society. Princeton / Oxford: Princeton University Press, S. 205–249.
PYBUS, Jennifer (2015): Accumulating Affect: Social Networks and their Archives of Feelings. In: Ken Hillis / Susanna Paasonen / Michael Petit (Hgg.): Networked Affect. Cambridge, Mass.: MIT Press, S. 235-249.
RÜHL, Manfred (1995): Rundfunk publizistisch begreifen. Reflexionstheoretische Überlegungen zum Primat programmierter Programme. In. Publizistik 40, 3, S. 279–304.
SEYFERT, Robert et al. (2019): On studying algorithms ethnographically. In: Organization 26, 4, S. 590–617.
SEYFERT, Robert / ROBERGE, Jonathan (2016) (Hgg.): Algorithmic Cultures. Essays on Meaning Performance and New Technologies. London / New York: Routledge. Dt. ersch. als Algorithmuskulturen. Über die rechnerische Konstruktion der Wirklichkeit. Bielefeld: transcript 2017 (=Kulturen der Gesellschaft 26).
ZAHN, Angelika: Was bitte schön ist ein Algorithmus? Blogeintrag auf Codingkids.de vom 22.11.2018; vgl. www.codingkids.de/wissen/was-bitteschoen-ist-ein-algorithmus (07.01.2020).
ZUBOFF, Shoshana (2015): Big Other. Surveillance Capitalism and the Prospects of an Information Civilization. In: Journal of Information Technology 30, 1, S. 75–89.
ZUBOFF, Shoshana (2018): The Age of Surveillance Capitalism. The Fight for the Future at the New Frontier of Power. London: Profile Books. Dt. ersch. als: Das Zeitalter des Überwachungskapitalismus. Frankfurt: Campus 2018.
ZWEIG, Katharina (2019): Ein Algorithmus hat kein Taktgefühl. Wo künstliche Intelligenz sich irrt, warum uns das betrifft und was wir dagegen tun können. München: Heyne.
Kontakt zur Verfasserin:

|